#stablediffusion 完全に理解した pic.twitter.com/IR5yjnL07Y
— すぎゃーん💯 (@sugyan) August 31, 2022
ということで少し触って遊んでみたのでメモ。
Stable Diffusion をザックリ理解
先月公開された Stable Diffusion。
高精度で美しい画像を出力できる高性能なモデルながら、Google Colab などでも手軽に動かせるし、 Apple silicon でもそれなりに動かせる、というのが魅力だ。
中身については 以下の記事の "How does Stable Diffusion work?" 以降のところが分かりやすい。
図をそのまま引用させていただくと

という仕組みになっていて、受け取る入力は "User Prompt" と "Latent Seed" のみ。 前者が「どのような画像を生成するか」を決めて、後者で「どんなバリエーションでその画像を生成するか」を決めるような感じ。
User Prompt は [77, 768] の空間にエンコードされて、これを使って [4, 64, 64] の Gaussian noise を scheduler によって繰り返し denoise していくことで目標の画像のための "latent image representations" を生成していく。最後はこれを VAE(Variational Auto-Encoder) で拡大していくことで最終的な [512, 512, 3] の画像を得る。
この途中の scheduler による sampling がアルゴリズムによって結果の質が変わってきたりするし、回数が少なすぎると denoise が足りなくて汚い出力になったりする、というわけだ。
ともかく、重要なのはこの 2 つの入力だけで出力が決まるということ、そして prompt の入力は [77, 768] に embedding されたものが使われる、ということ。
prompt の文字列を工夫していくのも良いが、そこから embedding されて渡すものを直接指定してしまっても良いわけだ。
また、 Latent Seed の noise の方も少しずつ変えていくことで少しだけ違う感じの出力を得たりすることができそうだ。
自分は以前に StyeleGAN で latent space を変化させて生成画像の morphing などをやっていたので、それと同じようなことをやってみることにした。
Prompt 間での interpolation, morphing
まずは 2 つの異なる prompt から生成される画像の間を補間して繋いでみる。
#stablediffusion でmorphing: Kyoto <-> Tokyo pic.twitter.com/yiE77vjaPJ
— すぎゃーん💯 (@sugyan) September 5, 2022
(当然ながら、京都と東京の町並みを補間するからといって愛知や静岡の風景が生成されたりはしない。)
scripts/txt2img.py の中にある、prompt から画像を生成する部分のメインはここにある。
c = model.get_learned_conditioning(prompts)
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
samples_ddim, _ = sampler.sample(
S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code
)
x_samples_ddim = model.decode_first_stage(samples_ddim)
model.get_learned_conditioning() で与えられた prompt 文字列から [N, 77, 768] の Tensor に embedding されたものが得られる。 これを sampler (ここではデフォルトで使われる DDIMSampler を使用している) に与えて ddim_steps 回数の sampling を実行して [N, 4, 64, 64] の denoise された結果が得られる。これを model.decode_first_stage() に与えることで最終的な画像に使われる値が得られるようだ。
sampler.sample() には色々なパラメータがあるが、とにかく重要なのは conditioning (c) と x_T (start_code) だけ。これを変化させることで生成画像をコントロールしていく。
start_code の方はここでは固定した値を使うようにすることで、「何を描くか」だけを徐々に変化させていく様子を作れる。一度だけ乱数を生成してそれを繰り返し使うようにすると良い。
で、 c の方は 2 つの異なる prompt からそれぞれ embedding された値を取り出して、線形に変化させていく。
指定した c と start_code から生成画像だけを得るような関数を書いておくとやりやすい。
model のロード方法などについては割愛。
from contextlib import nullcontext import numpy as np import torch from PIL import Image from ldm.models.diffusion.ddim import DDIMSampler from ldm.models.diffusion.ddpm import LatentDiffusion def get_device() -> torch.device: ... def load_model() -> LatentDiffusion: ... model = load_model(...) def generate( c: torch.Tensor, start_code: torch.Tensor, ddim_steps: int = 50 ) -> Image: batch_size = 1 device = get_device() precision_scope = torch.autocast if device.type == "cuda" else nullcontext with torch.no_grad(): with precision_scope("cuda"): with model.ema_scope(): uc = model.get_learned_conditioning(batch_size * [""]) shape = [4, 64, 64] samples_ddim, _ = DDIMSampler(model).sample( S=ddim_steps, conditioning=c, batch_size=batch_size, shape=shape, verbose=False, unconditional_guidance_scale=7.5, unconditional_conditioning=uc, eta=0.0, x_T=start_code, ) x_samples_ddim = model.decode_first_stage(samples_ddim) x_samples_ddim = torch.clamp( (x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0 ) image = ( 255.0 * x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()[0] ).astype(np.uint8) return Image.fromarray(image)
ちなみに、 sampler.sample() された結果の方を線形に繋いで変化させていくという手法もあるのだけど、これはもはやどんな画像が生成されるかほぼ決定された後の値なので、 morphing しても単なる画像合成のような感じにしかならなくて面白くはない。
指定した c や start_code で画像を生成する準備ができたら、あとはその入力を作っていくだけ。
def morph_prompts(prompts: Tuple[str, str], steps: int) -> None: start_code = torch.randn([1, 4, 64, 64], device=get_device()) c0 = model.get_learned_conditioning(prompts[0]) c1 = model.get_learned_conditioning(prompts[1]) for i in range(steps + 1): x = i / steps c = c0 * (1.0 - x) + c1 * x img = generate(c, start_code) img.save(f"morphing_{i:03d}.png")
これらを繋げてアニメーションさせれば、2 つの異なる prompt 間の morphing が出来上がる。
ただ、似ているものならまだあまり違和感ないが あまりに異なる 2 つを morphing させようとすると、急激に変化してしまって面白くない。
#stablediffusion でmorphing: apple <-> ??? pic.twitter.com/XcjyZ2iHqY
— すぎゃーん💯 (@sugyan) September 5, 2022
embedding された空間がどんなものかは未知だが、ともかく A と B の 2 点間には必ず「denoise された結果 A になるもの」と「denoise された結果 B になるもの」が分断される地点がどこかに存在してしまう。 それは A B の中心かもしれないし、少しズレたところかもしれないが、そのあたりで急激な変化が起こり得る。 ので、中点に近い位置は出来るだけ細かい step で刻んだ方がよりシームレスな morphing になりやすいように感じた。 ので、単純な線形に繋ぐのではなく双曲線関数で刻み幅を微妙に変えながら作ってみることにした。
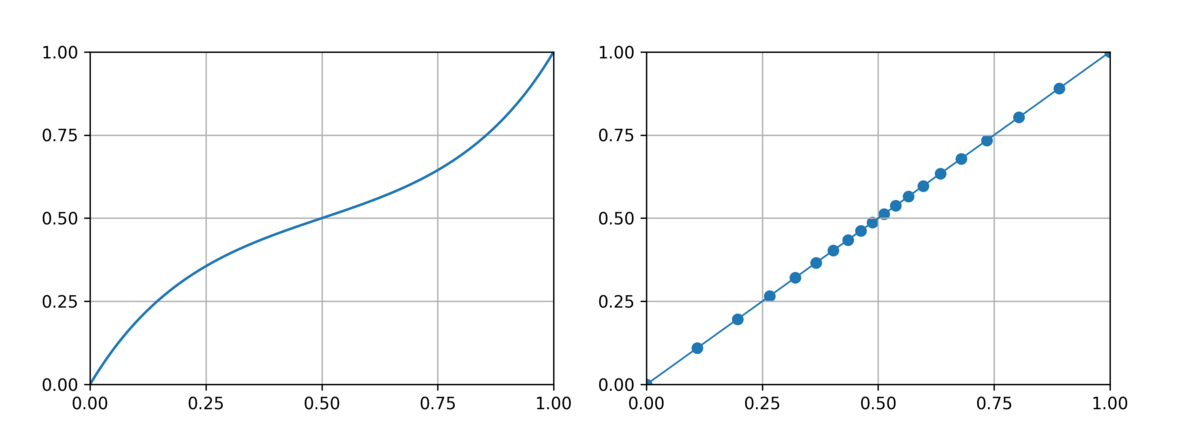
a = np.arccosh(5.0) for i in range(steps + 1): t = i / steps x = sinh(a * (t * 2.0 - 1.0)) / sinh(a) / 2.0 + 0.5 c = c0 * (1.0 - x) + c1 * x ...
それでもやっぱり急激な変化は捉えられないことが多々あるけれども…。
Seed 間での interpolation, morphing
今度は、同一の prompt で異なる Latent Seed を使用した 2つの画像間での morphing。
#stablediffusion で morphing between noises, by anime girl pic.twitter.com/iGDtLXU02Y
— すぎゃーん💯 (@sugyan) September 6, 2022
prompt の方は固定して、 torch.randn() で生成していた Gaussian noise の方を徐々に変えていく。生成する画像の「お題」は一緒だが、違うバリエーションのものになっていく、という morphing。
prompt のときと同じように変化させていけば良いだけ、と思ったが そうはいかない。実際やってみると中間点あたりはボヤけた画像になってしまうようだ。
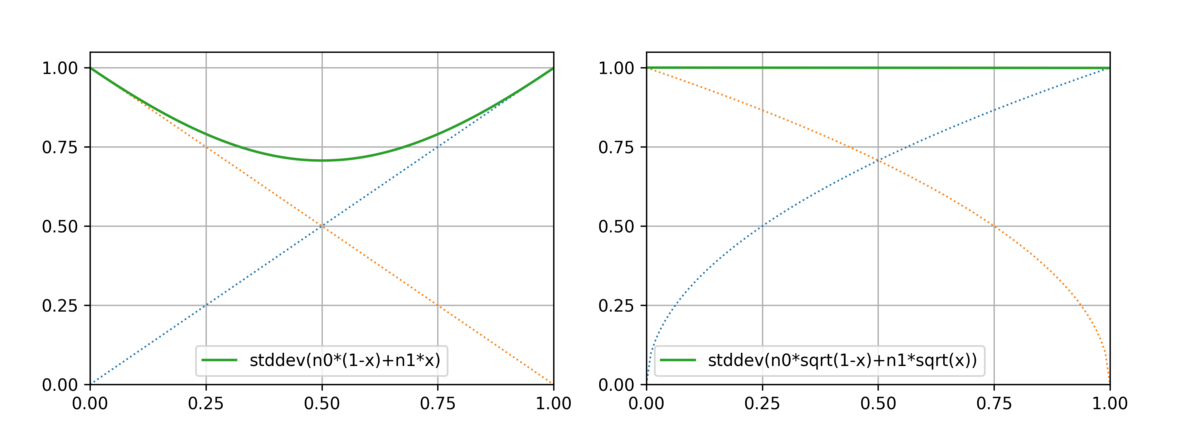
最初 何故だろう…?と思ったが どうやらこの noise は "Gaussian noise" であることが重要で、標準正規分布として になっていなければならない、ということらしい。
単純に
v0 * (1.0 - x) + v1 * x のように単純な線形結合で変化させていくと、中心に近づくにつれてその標準偏差は小さくなってしまう。
それを防ぐために、足し合わせる前にそれぞれの倍率の sqrt をとるようにすると、合成された noise は標準偏差を保持したまま遷移することができそうだ。
すると今度は 0 付近と 1 付近で急激な変化が起こりやすそうなので、 prompt morphing のときのように刻み幅を調節する。
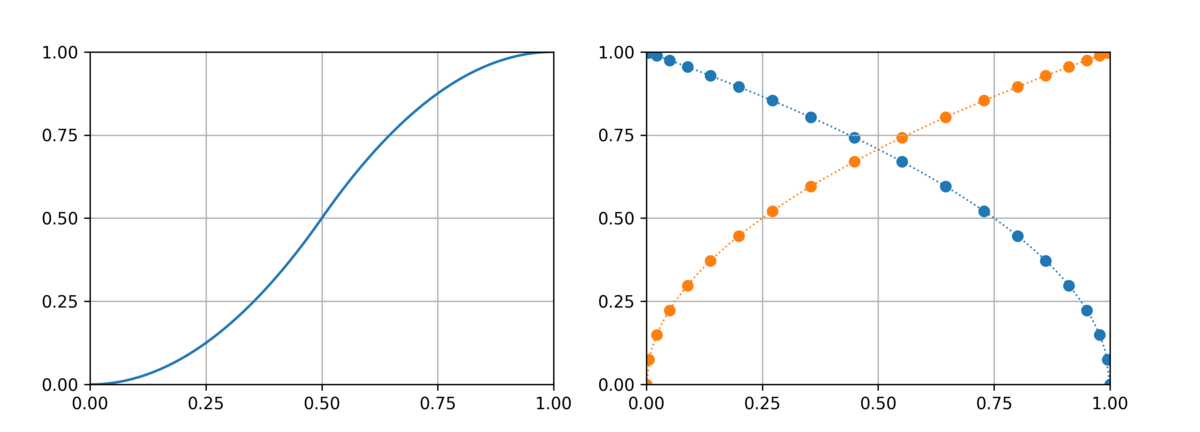
def morph_noises(prompt: str, steps: int) -> None: c = model.get_learned_conditioning([prompt]) n0 = torch.randn([1, 4, 64, 64], device=get_device()) n1 = torch.randn([1, 4, 64, 64], device=get_device()) for i in range(steps + 1): t = i / steps x = 2.0 * t**2 if t < 0.5 else 1.0 - 2.0 * (1.0 - t) ** 2 start_code = n0 * math.sqrt(1.0 - x) + n1 * math.sqrt(x) img = generate(c, start_code) img.save(f"morphing_{i:03d}.png")
これで、同じお題(prompt)に対して複数のバリエーションで描かれたものを連続的に変化させていくことができる。 好みの画像を出力する seed を幾つかピックアップして繋いでみたりするとより好みのものが見つかるかもしれないし、意外とブレンドされたものは好みではないものになるかもしれない。
※追記
まとめ
以上の2つができれば、その応用として prompt と noise を同時に変化させていったり、交互に変化させていったり、数回変化させた後にまた元の画像に戻ってきたり、といったものも作っていける。
雑に試行錯誤しながら実行できるように Google Colab でscriptを書いていたけど、ちょっと整理して公開する予定(需要あるかどうか分からないけど)。 prompt 間の morphing はやっている人結構いるけど、noise 間のものはまだあんまり見かけないような気はする?
※追記: GitHub - sugyan/stable-diffusion-morphing でとりあえず公開しておきました。多分動くはず?