
の記事の続き(?)。 ある程度の学習データを収集して学習させたモデルが出来たので、それを使って実際に色々やってみる。
StyleGAN2-ADA
前回の記事でも書いたけど、厳選した16,000枚の画像を使って StyleGAN2-ADA を使って生成モデルを学習させてみた。
これは StyleGAN2 から進化したもので、より少ない枚数からでも安定して学習が成功するようになっていて、さらにparameter数など調整されて学習や推論もより早くなっている、とのこと。
それまでのStyleGANシリーズはTensorFlowで実装されていたが、最近はPyTorchに移行しつつある?のか、今はPyTorch版が積極的に開発進んでいるようだ。 そういう時代の流れなのか…。
今回は最初に触ったのがTensorFlow版だったのでまだPyTorch版は使っておらず、本記事はすべてTensorFlowだけを使っている。
学習
256x256程度のサイズのものであれば、Google Colabでも適度にsnapshotを残しながら学習しておき 切断されたら休ませてまた続きから学習始める、を繰り返せば数日〜数週間でそれなりに学習できる感じだった。
512x512やそれ以上のサイズだとちょっと厳しいかもしれない。
mapping出力と生成画像
StyleGAN2学習済みモデルを使ったmorphing、latent spaceの探求 - すぎゃーんメモ の記事で書いたが、StyleGAN の generator は、"mapping network" と "synthesis network" の2つの network によって作られている。 実際に画像を生成するのは synthesis network の方で、前段の mapping network は乱数入力を synthesis network への入力として適したものに変換するような役割になっている。
どちらの入力も潜在空間(latent space)としてみなせるが、 synthesis network への入力(= mapping network の出力)の方が次元数も多く、より表現力を持つものになっている。 この dlatents (disentangled latents) と呼ばれるものを線形に変化させることでスムーズなmorphingを表現できることを前述の記事で確かめた。
ということはこの dlatents の中に生成画像の属性を決定させるような要素があり、例えば顔画像生成のモデルの場合は顔の表情や向きなどを表すベクトルなどが存在しているかもしれない。 というのが今回のテーマ。
生成画像の属性推定結果から潜在空間の偏りを抽出
今回試したのは、以下のような手法。
- 生成モデルを使ってランダムに数千〜数万件の顔画像を生成
- このとき、生成結果とともに dlatents の値もペアで保存しておく
- 生成結果の画像すべてに対し、顔画像の属性を推定する
- 推定結果の上位(または下位)数%を抽出し、それらを生成した
dlatentsたちの平均をとる
例えば表情に関する属性の場合、各生成結果の画像の「笑顔度」のようなものを機械的に推定し(もちろん手動で判別しても良いが、めちゃめちゃ高コストなので機械にやってもらいたい)、それが高scoreになっているものだけを集めて それらを生成した dlatents たちの平均値を計算する。 その値は、あらゆる顔画像を生成する dlatents の平均値と比較すると、笑顔を作る成分が強いものになっている、はず。
今回はまず学習済み生成モデルを使って適当な乱数から 20,000件の顔画像を生成し、それらに対して各属性を推定し、その結果で上位(または下位)0.5% の 100件だけを抽出するようにしてみた。 ものによってはもっとサンプル数が多く必要だったり、もっと少なくても問題ない場合もあるかもしれない。
表情推定
顔画像から表情を推定するモデルは幾つかあったが、今回は pypaz を利用した。
表情推定だけでなく、keypoint estimationやobject detectionなど様々な視覚機能を盛り込んでいて、それらを抽象化されたAPIで使えるようにしている便利ライブラリのようだ。
ここでは表情推定の部分だけを使用した。
import pathlib from typing import Dict, List import dlib import numpy as np import paz.processors as pr from paz.abstract import Box2D from paz.backend.image import load_image from paz.pipelines import MiniXceptionFER class EmotionDetector(pr.Processor): # type: ignore def __init__(self) -> None: super(EmotionDetector, self).__init__() self.detector = dlib.get_frontal_face_detector() self.crop = pr.CropBoxes2D() self.classify = MiniXceptionFER() def call(self, image: np.ndarray) -> List[np.ndarray]: detections, scores, _ = self.detector.run(image, 1) boxes2D = [] for detection, score in zip(detections, scores): boxes2D.append( Box2D( [ detection.left(), detection.top(), detection.right(), detection.bottom(), ], score, ) ) results = [] for cropped_image in self.crop(image, boxes2D): results.append(self.classify(cropped_image)["scores"]) return results def predict(target_dir: pathlib.Path) -> Dict[str, np.ndarray]: results = {} detect = EmotionDetector() for i, img_file in enumerate(map(str, target_dir.glob("*.png"))): image = load_image(img_file) predictions = detect(image) if len(predictions) != 1: continue print(f"{i:05d} {img_file}", predictions[0][0].tolist()) results[img_file] = predictions[0][0] return results
paz.processors として定義されたDetectorが、dlibで顔領域を検出した上でその領域に対し paz.pipelines.MiniXceptionFER によって表情を推定した結果を返してくれる。
MiniXceptionFER から返ってくるのは ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral'] の7 classesでの分類結果。
この結果で happy が1.0に近いものが得られたなら、それは確信度高く笑顔である、ということなので、その顔を生成した dlatents を集めて平均値を算出し、全体平均からの偏りをvectorとして抽出した。
これをmapping出力に加えていくことで、ランダムな生成顔画像も笑顔に変えていくことができた。
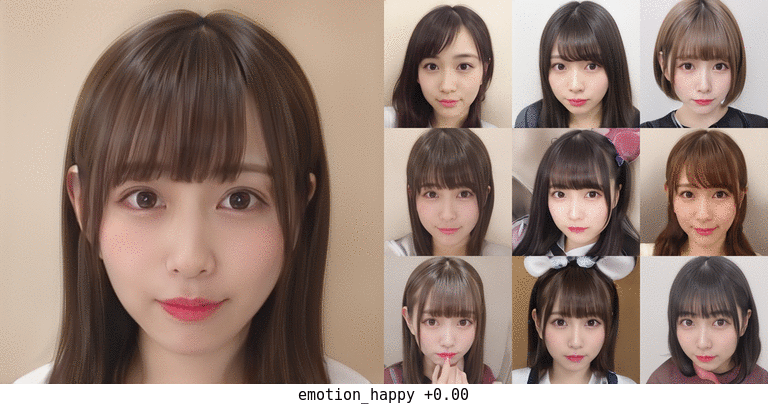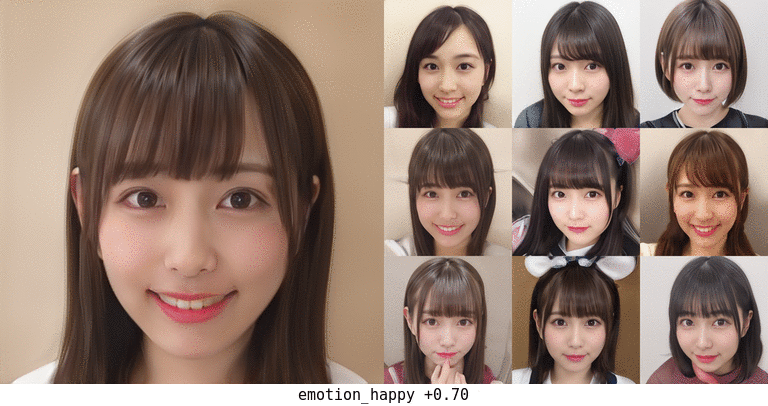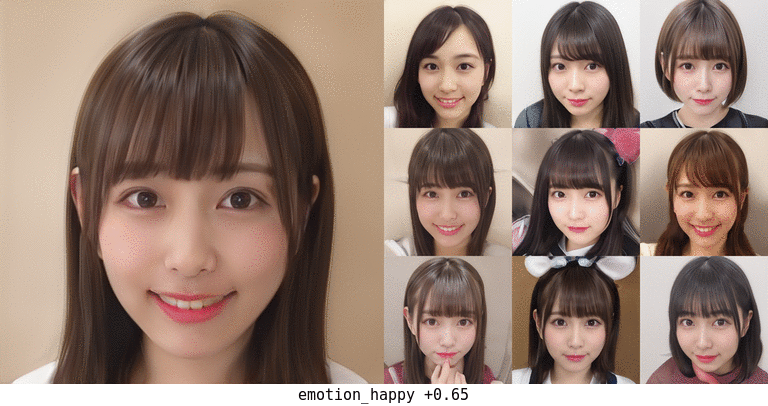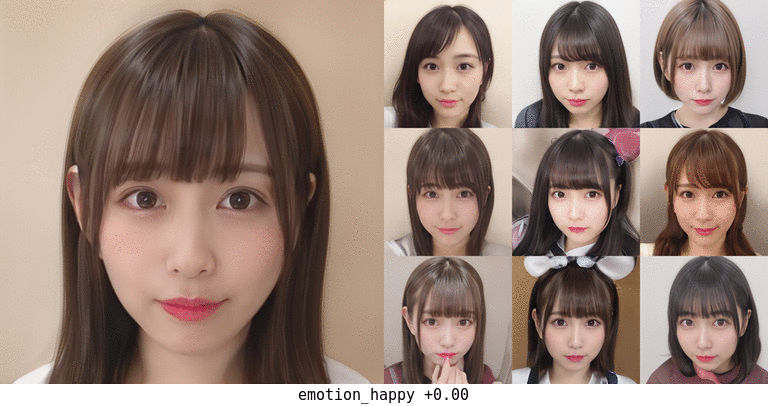
顔の向きや髪型も多少は影響を受けているが、概ね顔の特徴はそのままで主に口と目?あたりだけが変化している。 最初から笑顔だったものはより笑顔に、無表情だったものも口角が上がるくらいにはなっている。 口が開いて前歯が見えるようになったりするのも興味深い。
ちなみに他の表情に関しては、同様のことをやっても「怒っている顔」や「悲しい顔」のようなものは作れなかった。 まず、今の生成モデルの学習のために収集し厳選したデータは大部分が笑顔か無表情の顔画像であったため(悲しい顔ばかり載せているようなアイドルは居ない)、生成される画像も多くはそのどちらかであり、それ以外の表情の画像はほぼ生成されない。 ので、機械推定した結果もそれらの表情を強く検出するものはなく、笑顔のようにベクトルを抽出することは難しいようだ。
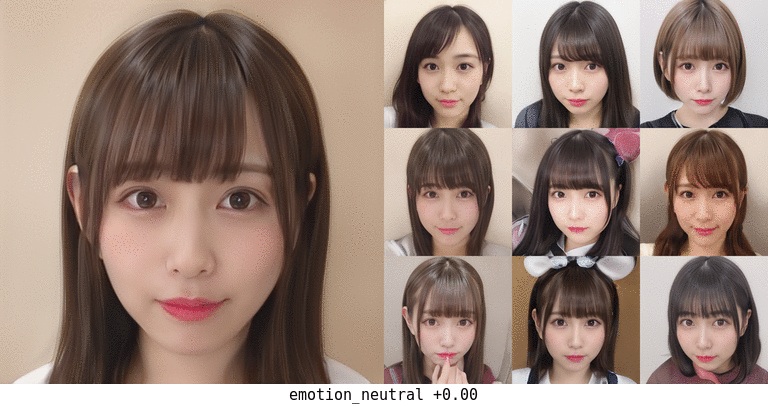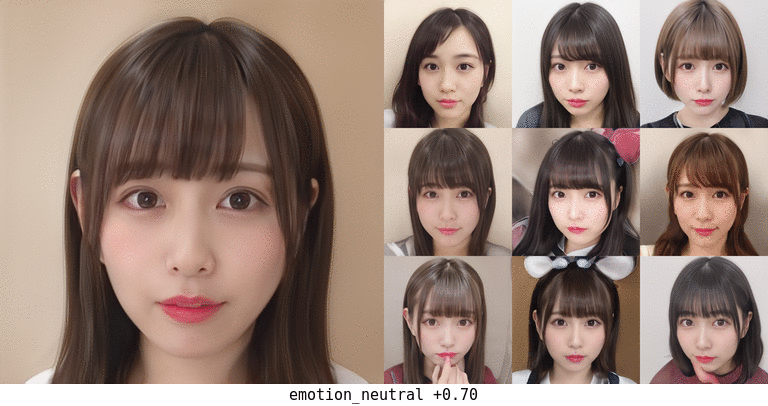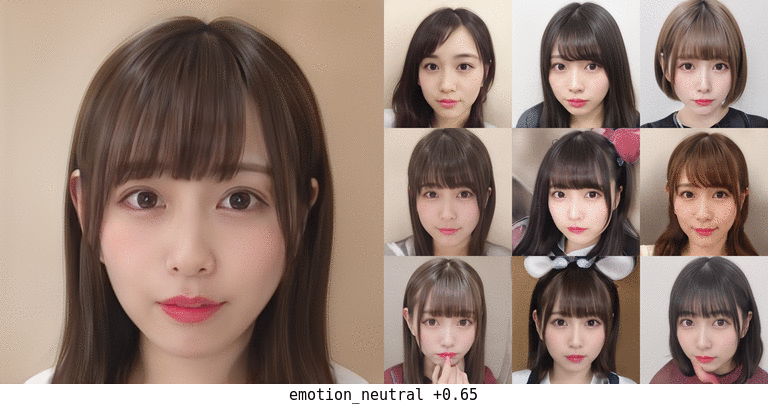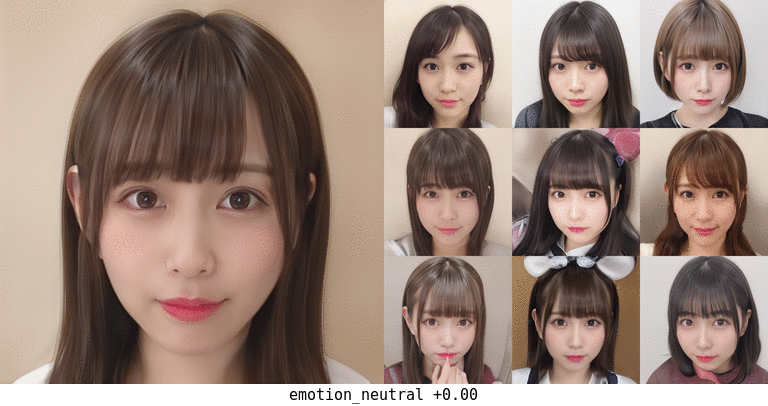
無表情化の場合。元が笑顔のものが真顔になる程度の変化は一応ありそう。 真ん中上段の子は前髪がだいぶアレだが…。

悲しみ。少し笑顔が消えて眉が困ってそうな感じになっているようには見える。 が、とても微妙…。

怒り。何故か顔の向きばかり変化してしまっているが、結局表情はほとんど変化が無いようだ。
・結果まとめ
笑顔に関しては概ね上手く抽出できた。 その他の表情についてはほとんど良い結果にならなかったが、学習データに使う顔画像の表情がもっと豊富にあればそういった顔画像も生成できて抽出が可能になると思われる。
顔姿勢推定
顔の向きも推定して同様のことをしてみる。
機械学習モデルでも顔角度の推定できるものありそうだが、今回は dlib で検出したlandmarkの座標から計算する、というものをやってみた。
詳しくは以下の記事を参照。
ほぼこの記事の通りに実装して、入力画像から yaw, pitch, roll のEuler anglesを算出する。
参照している3Dモデルの座標や数によって精度も変わってきそうだが、とりあえずは上記記事で使われている6点だけのものでそれなりに正しく角度が導き出せるようだった。
import math import pathlib from typing import List import cv2 import dlib import numpy as np class HeadposeDetector: def __init__(self) -> None: predictor_path = "shape_predictor_68_face_landmarks.dat" self.model_points = np.array( [ (0.0, 0.0, 0.0), # Nose tip (0.0, -330.0, -65.0), # Chin (-225.0, 170.0, -135.0), # Left eye left corner (225.0, 170.0, -135.0), # Right eye right corne (-150.0, -150.0, -125.0), # Left Mouth corner (150.0, -150.0, -125.0), # Right mouth corner ] ) self.detector = dlib.get_frontal_face_detector() self.predictor = dlib.shape_predictor(predictor_path) def __call__(self, img_file: pathlib.Path) -> List[float]: image = cv2.imread(str(img_file)) size = image.shape # 2D image points points = [] rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) dets = self.detector(rgb, 1) if len(dets) != 1: return [np.nan, np.nan, np.nan] d = dets[0] shape = self.predictor(rgb, d) for i in [30, 8, 36, 45, 48, 54]: points.append([shape.part(i).x, shape.part(i).y]) image_points = np.array(points, dtype=np.float64) # Camera internals focal_length = size[1] center = (size[1] / 2, size[0] / 2) camera_matrix = np.array( [[focal_length, 0, center[0]], [0, focal_length, center[1]], [0, 0, 1]], dtype=np.float64, ) # Calculate rotation vector and translation vector dist_coeffs = np.zeros((4, 1)) # Assuming no lens distortion success, rotation_vector, translation_vector = cv2.solvePnP( self.model_points, image_points, camera_matrix, dist_coeffs, flags=cv2.SOLVEPNP_ITERATIVE, ) # Calculate euler angles rotation_mat, _ = cv2.Rodrigues(rotation_vector) _, _, _, _, _, _, euler_angles = cv2.decomposeProjectionMatrix( cv2.hconcat([rotation_mat, translation_vector]) ) return [ math.degrees(math.asin(math.sin(math.radians(a)))) for a in euler_angles.flatten() ]
表情と同様に、値の大きなものを生成した dlatents の平均、値の小さなものを生成した dlatents の平均、を使って顔向きを変化させるベクトルを求める。

yaw (左右向き)。全体の大きさが変わってしまうので連続的に動くと不自然に感じてしまうが、ともかく顔の特徴はそのままに向きだけが変化しているのは観測できる。 顔の向きが変わっても視線は固定されている。

pitch (上下向き)。yawほど顕著に差は出ないが、それなりには変化する。 真ん中上段の子の前髪はやはりハゲやすいようだ…。

roll (傾き?)。これは首を傾けるように変化するはずのものだが、そもそも 学習データの前処理の段階 で正規化されているので傾いた画像が生成されるはずがない。 ので表情のときと同様に正しくベクトルを抽出できず、結果的に何故かyawと似たような動きになってしまっている。
・結果まとめ
yaw, pitch それぞれに関しては概ね上手く抽出できた。yawの方が学習データのバリエーションが多かったからか、より顕著に差が出るようだった。
髪領域推定 (顔解析)
次は髪色、髪の長さなどを変化させたい。 これらの属性を数値として得るには、まず髪の領域を抽出する必要がある。
ここでは、TensorFlowで動かせる学習済みモデルとして face_toolbox_keras を使用した。
これもpypazのように顔やlandmarkの検出など様々な機能があるが、その中の一つとして Face parsing がある。
元々は https://github.com/zllrunning/face-parsing.PyTorch で、それを移植したものらしい。
この Face parsing は入力の顔画像から「目」「鼻」「口」など約20のclassに各pixelを分類する。
髪の領域は値が 17 になっているので、その領域だけを抽出することで顔画像から髪の部分だけを取り出すことができる。
髪の領域だけ得ることができれば、あとは
- その面積で「髪のボリューム」
- 下端の位置・下端の幅で「髪の長さ」
- 画素の平均値で「髪色の明るさ」
などを数値化できる。 顔姿勢と同様に、値の大きなものを生成した dlatents の平均、値の小さなものを生成した dlatents の平均、を使ってベクトルを求める。
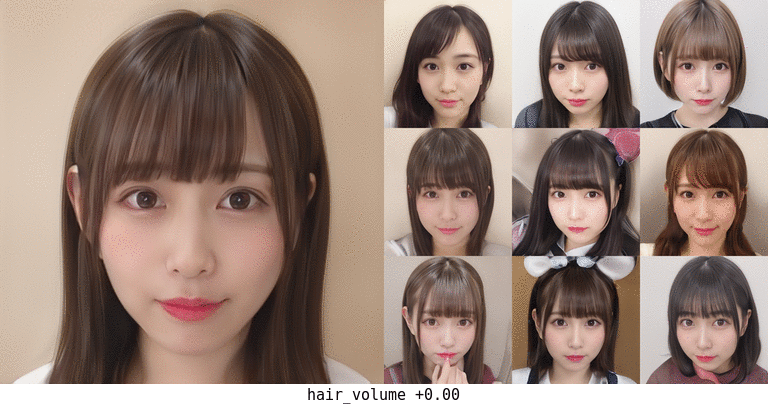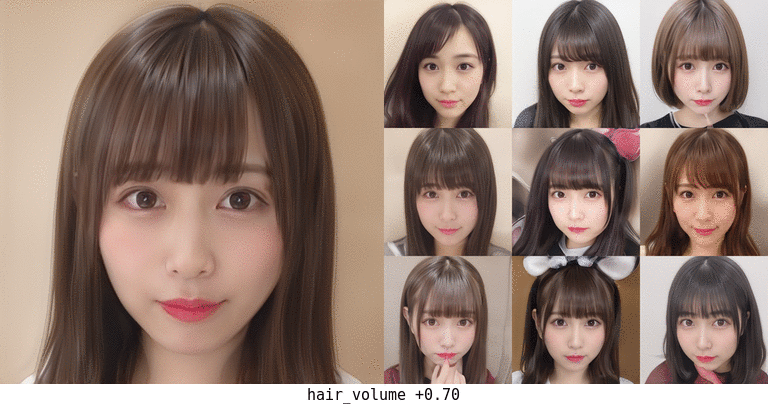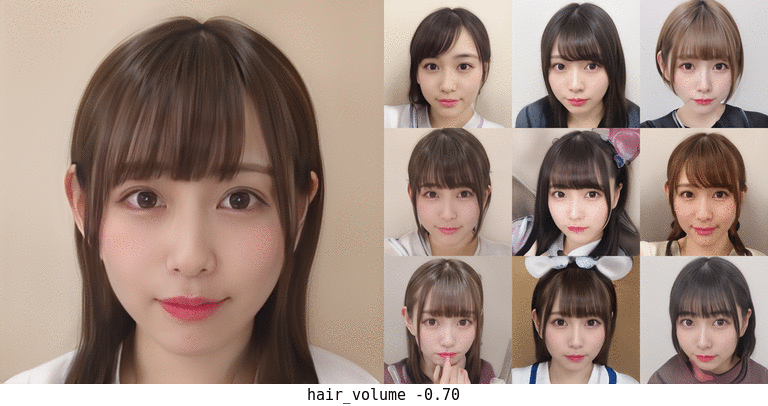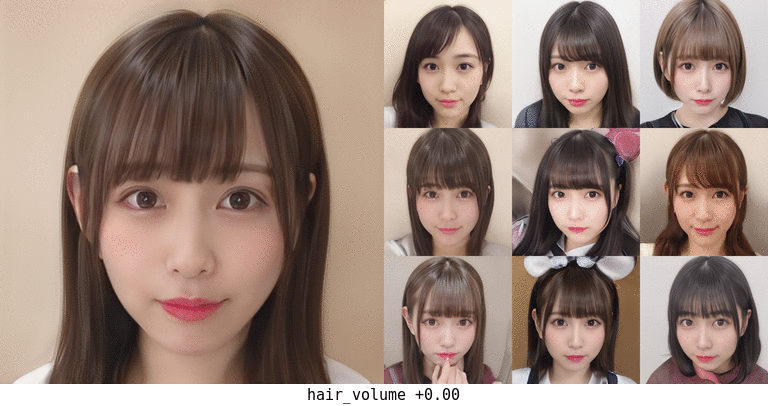
ボリューム。面積だけで計算しているのでちょっと頭の形が変になったりするかもしれない…。

長さ。ボリュームよりは自然な感じで長さが変化しているように見える。 真ん中上段の子の前髪はやはり(ry

明るさ。暗くするとみんな黒髪になるし、明るくすると茶髪や金髪など様々な明るい色になる。
・結果まとめ
髪の領域を推定することで、髪に関する属性を計算することができて長さや色などを変化させることができた。 もう少し頑張って上手く数値化できれば、前髪の具合や触覚の有無指定などもできるようになるかもしれない。
年齢 (上手くいかず)
これも他と同様、理論的には「顔画像から年齢を推定し、高い数値のものを生成した dlatents と 低い数値のものを生成した dlatents からベクトルを抽出」という感じで 童顔にしたり大人びた顔にしたりできると思っていたのだけど、そもそもの年齢の推定が全然正確にできなそうで断念した…。
など幾つかの学習済みモデルを使って年齢推定をかけてみたのだけど、どれも「東アジアの10〜20代女性」の学習データが乏しいのもあるのか(もしくは使い方が悪かった…?)、結果のブレが激しくて とても正しい年齢推定ができている感じがしなかった。
生成の学習に使ったデータからある程度は年齢ラベルつけたデータセットは作れるので、頑張れば年齢推定モデルを自前で学習させて より正確な推定ができるようになるかもしれないが… そこまでやる気にはならなかったので諦めた。
複合
とりあえずはここまでで
- 表情 (笑顔◎、無表情△)
- 顔角度 (左右◎、上下○)
- 髪 (長さ◎、明るさ◎)
といった属性については変化させるためのベクトルが抽出できた。 ので、複数を足し合わせたりすることもできる。

無表情 + 右上向き + 髪短く明るく

笑顔 + 下向き + 髪長く暗く
というわけで、記事の冒頭に貼った画像は元は同じ顔からこうして変化させて作ったものでした。