「だんご屋のひまつぶし」とは
「ハノイの塔」の派生型のようなパズル。 高さ3の串が3本あり、3色の団子2個ずつ計6個が刺さっている。これらを1個ずつ移し替えて、ある状態からある状態へと遷移させる、というゲーム。
- 移動できるのは各串で一番上にある団子だけ。
- 団子の大きさのような概念はなく、高さ3以内であればどこにでも動かせる。
単純なルールだがなかなかに奥が深く、じっくり考えて動かさないと最適な手順で達成するのは意外に難しい。
パズルオーディションというもので最優秀賞を受賞した作品らしい。 www.jpuzzle.jp
これがめでたく商品化されたもの、のようだ。
 【最優秀賞受賞】 だんご屋のひまつぶし 脳トレパズル ビバリー お部屋においてもかわいいスタンド付き")
最長手順の問題は…?
「だんご屋のひまつぶし」の中には問題集が同梱されており、始点と終点を指定した全52問の問題が収録されている。序盤の「初級」は最短5〜6手程度だが、最後の「特級」は最短でも14手の手順が必要なものとなっている。
ここで疑問が湧いたので考えてみることにした。
「だんご屋のひまつぶし」というパズルを妻が見つけて、面白そうだったので買ってみた。(知育にもなるかな?と思ったが子どもたちは団子をぶん投げて遊ぶだけだった…。) be-en.co.jp/products/bog... ルールは簡単で、高さ3の3本の串に積まれた2個ずつ3色のだんごを、1個ずつ他の串に移動して ある状態からある状態に変えられるか、というもの。同梱の問題集には難易度ごとに52問のものが載っている。 最高難度のものは14手、だったのだが 果たしてこれが最長なのだろうか?という疑問が湧いたので考えてみたい。
— すぎゃーん (@sugyan.com) October 9, 2024 at 10:20 PM
[image or embed]
組み合わせ、グラフ問題
まず、この「(高さ3)×(3本)の串に、(3色)の団子(2個)ずつを積む」という条件で、何種類の状態があるかを考える。
だんごの数の配置だけを考えると、左から [3, 3, 0] の他、
[3, 0, 3],[0, 3, 3]の2本が埋まって1本が空のパターン[2, 2, 2]の同数で埋まっているパターン[3, 2, 1],[2, 3, 1], ... のようなパターン 全6通り
で合計 10通り が存在することがすぐにわかる。
(ちなみに問題集では 最後の [3, 2, 1] のようなパターンが始点・終点に指定されるものは存在していない)
次に6個の団子の並び方を考える。
最初の色で6個のうち2個を選ぶのが 6C2 = 15 通り、次の色で残った4個から2個を選ぶのが 4C2 = 6 通り、最後の色は 2C2 = 1 通りで、これらを掛け合わせた 15 * 6 * 1 = 90 通りが存在する。
よって、それぞれの配置パターン10通りに、それぞれ90通りの並び方が存在するので、有り得る状態の組み合わせは全部で 900通り となる。
ある状態から団子を他の串へ移動する操作は、この900通りある中で別の状態へと遷移する操作、ということになる。1回の操作で遷移できる状態同士を辺として繋ぐことで、900頂点の無向グラフを構築することができる。 そうすると、「ある状態からある状態へ遷移させる最短の手順」は、このグラフ上での最短経路を求めることに相当する。
ということで、このパズルの問題の最適解の導出はすべてグラフ上での最短経路問題であり、最長手順の問題を考えるのは、このグラフの「直径」を求めることに相当する。
プログラムで解く
最短経路を求めるグラフ問題と分かれば、プログラムで簡単に解くことができる。
状態の列挙
まずは、900通りの全状態を列挙する。
並び替えの列挙は、ここでは同色のものを区別しないため、先にそれぞれの個数をカウントしておいてからそれを使ってbacktrackingで列挙する。
use std::collections::BTreeMap; pub fn unique_permutations(elems: Vec<u8>) -> Vec<Vec<u8>> { fn backtrack( n: usize, curr: &mut Vec<u8>, counts: &mut BTreeMap<u8, u32>, result: &mut Vec<Vec<u8>>, ) { if n == 0 { return result.push(curr.clone()); } for key in counts.keys().copied().collect::<Vec<_>>() { if counts[&key] == 0 { continue; } counts.entry(key).and_modify(|e| *e -= 1); curr.push(key); backtrack(n - 1, curr, counts, result); curr.pop(); counts.entry(key).and_modify(|e| *e += 1); } } let mut result = Vec::new(); let mut counts = BTreeMap::new(); for &elem in &elems { *counts.entry(elem).or_insert(0) += 1; } backtrack( elems.len(), &mut Vec::with_capacity(elems.len()), &mut counts, &mut result, ); result } #[cfg(test)] mod tests { use super::*; #[test] fn test_unique_permutations() { let perms = unique_permutations(vec![1, 1, 2, 2, 3, 3]); assert_eq!(perms.len(), 90); } }
そして、配置個数のパターンは上限つきの整数分割の列挙となる。こちらはbacktrackingするまでもないので再帰関数だけで列挙する。
pub fn bounded_partitions(len: usize, upper_limit: u32, target_sum: u32) -> Vec<Vec<u32>> { fn recursive( i: usize, upper_limit: u32, remain: u32, curr: &mut Vec<u32>, results: &mut Vec<Vec<u32>>, ) { if i == 0 { if remain == 0 { results.push(curr.clone()); } return; } for n in 0..=upper_limit.min(remain) { curr[i - 1] = n; recursive(i - 1, upper_limit, remain - n, curr, results); } } let mut results = Vec::new(); recursive( len, upper_limit, target_sum, &mut vec![0; len], &mut results, ); results } #[cfg(test)] mod tests { use super::*; #[test] fn test_bounded_partitions() { let partitions = bounded_partitions(3, 3, 6); assert_eq!(partitions.len(), 10); } }
これでそれぞれ列挙できたので、あとはこれらを組み合わせて各並び換えから各配置パターンを適用する。
let permutations = unique_permutations(vec![1, 1, 2, 2, 3, 3]); for stacks in bounded_partitions(3, 3, 6) .iter() .flat_map(|partition| { permutations.iter().map(|p| { let mut stacks = vec![Vec::new(); 3]; let mut iter = p.iter(); for (i, num) in partition.iter().enumerate() { for _ in 0..*num { stacks[i].push(*iter.next().unwrap()); } } stacks }) }) { println!("{:?}", stacks); }
これで900通りの状態が全列挙できる。
[[1, 1, 2], [2, 3, 3], []] [[1, 1, 2], [3, 2, 3], []] [[1, 1, 2], [3, 3, 2], []] [[1, 1, 3], [2, 2, 3], []] [[1, 1, 3], [2, 3, 2], []] [[1, 1, 3], [3, 2, 2], []] [[1, 2, 1], [2, 3, 3], []] [[1, 2, 1], [3, 2, 3], []] [[1, 2, 1], [3, 3, 2], []] [[1, 2, 2], [1, 3, 3], []] [[1, 2, 2], [3, 1, 3], []] [[1, 2, 2], [3, 3, 1], []] ...
ちなみに Pythonなら itertools とかを使って3行くらいで全列挙できそう。
>>> from itertools import islice, permutations, product, repeat >>> for perm, part in product(sorted(set(permutations([1, 1, 2, 2, 3, 3]))), (a for a in product(*repeat(range(4), 3)) if sum(a) == 6)): ... it=iter(perm) ... print(*tuple(list(islice(it, n)) for n in part)) ... [] [1, 1, 2] [2, 3, 3] [1] [1, 2] [2, 3, 3] [1] [1, 2, 2] [3, 3] [1, 1] [2] [2, 3, 3] [1, 1] [2, 2] [3, 3] [1, 1] [2, 2, 3] [3] [1, 1, 2] [] [2, 3, 3] [1, 1, 2] [2] [3, 3] [1, 1, 2] [2, 3] [3] [1, 1, 2] [2, 3, 3] [] [] [1, 1, 2] [3, 2, 3] [1] [1, 2] [3, 2, 3] [1] [1, 2, 3] [2, 3] ...
グラフの構築
次に、各状態間の遷移を辺としたグラフの構築を考える。
Vec をstackとして利用して、空でないstackから1つ pop して その要素を高さが上限に達しない他のstackへ push する、という操作で遷移先の状態を得られる。全状態に対して可能な全遷移を列挙する必要があるが、1状態から遷移可能なのは移動元の串の選択肢が3本で移動先がの選択肢が残る2本なので高々6通り。
#[derive(Hash, Eq, PartialEq)] struct State([Vec<u8>; 3]); impl State { pub fn next_states(&self, max_len: usize) -> Vec<Self> { let mut results = Vec::new(); for i in 0..3 { for j in 0..3 { if i == j || self.0[i].is_empty() || self.0[j].len() == max_len { continue; } let mut v = self.0.clone(); let ball = v[i].pop().unwrap(); v[j].push(ball); results.push(Self(v)); } } results } }
あとは全900通りの状態に振ったindexを使って、それぞれの状態から遷移可能な状態のindexの配列を持つようにしておくと、その後の計算が楽になる。
use std::collections::HashMap; struct Graph { nodes: Vec<State>, edges: Vec<Vec<usize>>, } impl Graph { pub fn new(nodes: Vec<State>, max_len: usize) -> Self { let mut edges = vec![Vec::with_capacity(6); nodes.len()]; let node_map = nodes .iter() .enumerate() .map(|(i, node)| (node, i)) .collect::<HashMap<_, _>>(); for src in &nodes { for dst in src.next_state(max_len) { edges[node_map[src]].push(node_map[&dst]); } } Self { nodes, edges } } }
これで、 900頂点 3,240辺のグラフが構築できた。
最短経路問題を解く
あとは、有名な Dijkstra's algorithm を使えば、任意の始点から各頂点への最短距離(とその経路も)を求めることができる。
use std::cmp::Reverse; use std::collections::BinaryHeap; impl Graph { fn distances(&self, src: usize) -> Vec<Option<u32>> { let mut distances = vec![None; self.nodes.len()]; let mut bh = BinaryHeap::new(); distances[src] = Some(0); bh.push((Reverse(0), src)); while let Some((Reverse(d), i)) = bh.pop() { for &j in &self.edges[i] { if distances[j].is_none() { distances[j] = Some(d + 1); bh.push((Reverse(d + 1), j)); } } } distances } }
グラフの直径、すなわち全頂点対に対する最短経路のうち最長のもの、を求めるには Floyd–Warshall algorithm がよく知られていると思うが、このグラフの場合は頂点数に対して辺数が少なめなので、全頂点を始点としてDijkstraを使った方がむしろ計算量は少ないようだった。
どちらにしろこの程度の規模なら手元のPCでも十分に速く、900 * 900 = 810,000 通りのすべての始点・終点の組み合わせでの最短距離を求めるのに 50ms程度で計算が終わる。
そして以下のような結果が得られた。
distance 0: 900 distance 1: 3240 distance 2: 7128 distance 3: 13716 distance 4: 21924 distance 5: 32544 distance 6: 48636 distance 7: 72684 distance 8: 90162 distance 9: 99990 distance 10: 115788 distance 11: 108144 distance 12: 88266 distance 13: 66816 distance 14: 33618 distance 15: 6264 distance 16: 180 total: 810000
ということで、最短手順が16手の組み合わせが存在することが分かった。
WASM化して、ブラウザ上で解く
この程度の計算量ならJavaScriptで書いてもそれなりに速く動くとは思うが、せっかくRustで書いたので wasm-pack を使ってWASMにして、ブラウザ上で動かしてみることにした。
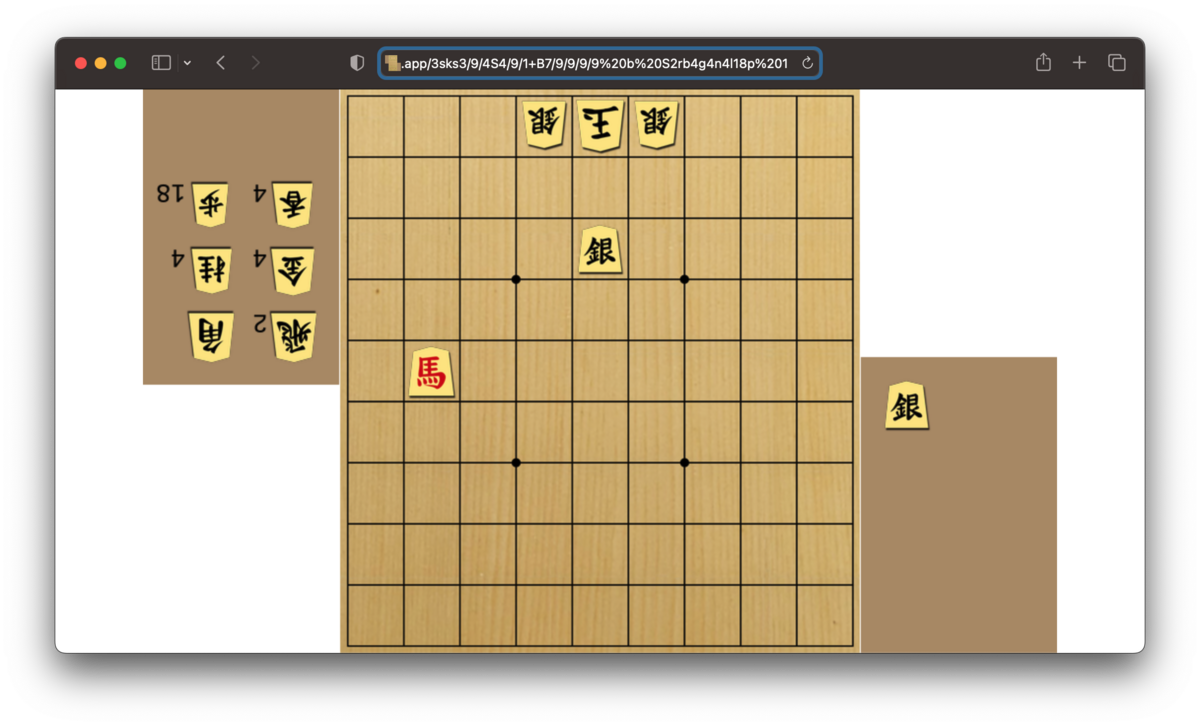
始点と終点をドラッグ&ドロップで編集すると、瞬時に最短手順を解いて示してくれる。URLのqueryで指定もできる。
例えば、最長の16手の問題とその最短解の例。
WASMをロードしてグラフまで構築してしまえば、始点指定してのDijkstraは百μs程度で探索できるのでWebWorkerなどに移譲する必要すら無い。 各nodeへの最短距離を計算する際に遷移元のnode情報も記録しておけば、再帰的に逆に辿ることで経路も(あくまで1例だが)求めることができる。
もしもすべて異なる団子だったら
ここからは「だんご屋のひまつぶし」から離れて考えていく。
「3色の団子2個ずつ計6個」という条件で計算していたが、これがもし「すべて異なる6色」に塗り分けられているものだったらどうなるだろうか。
団子の総数は変わらないので配置パターンは同じ10通りだが、並べ替えの列挙が 6C2 * 4C2 * 2C2 = 15 * 6 * 1 = 90 通りだったのが、 6! = 720 通りに増えることになる。つまり状態数が8倍の 7200通り に増えることになる。
上述のようなプログラムで解く場合、 vec![1, 1, 2, 2, 3, 3] としていた入力を vec![1, 2, 3, 4, 5, 6] に変えるだけで良い。
7,200頂点 25,920辺 のグラフが構築され、最長19手の問題が存在することが分かる。
distance 0: 7200 distance 1: 25920 distance 2: 64800 distance 3: 138240 distance 4: 257040 distance 5: 437760 distance 6: 738720 distance 7: 1311120 distance 8: 2088720 distance 9: 2954880 distance 10: 4080240 distance 11: 5700240 distance 12: 6947280 distance 13: 7223040 distance 14: 7778160 distance 15: 6809760 distance 16: 3745440 distance 17: 1298160 distance 18: 224640 distance 19: 8640 total: 51840000
最長19手は 8,640通りがあるが、始点を [[1, 2, 3], [4, 5, 6], []] のように固定すると4通りだけに絞られ、あとはこれらの並び順や配置される串が入れ替わるだけで本質的に同じ問題となる。
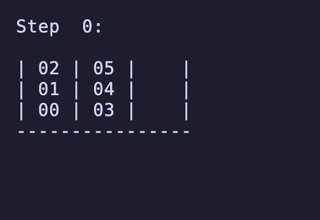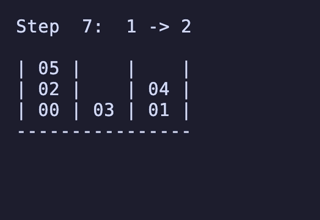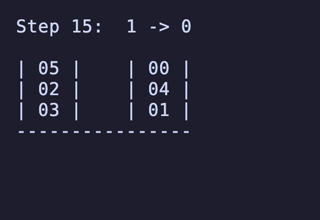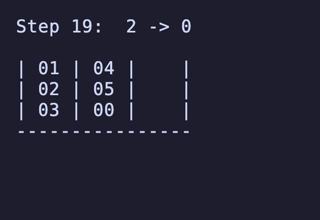
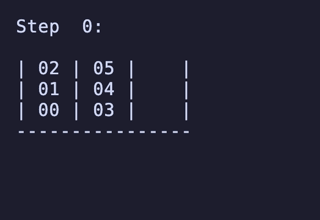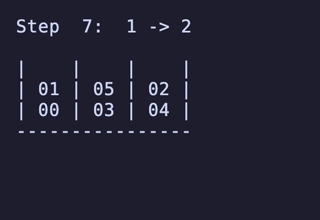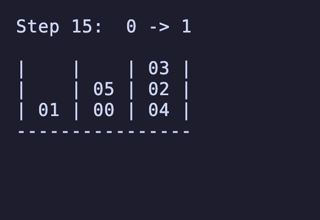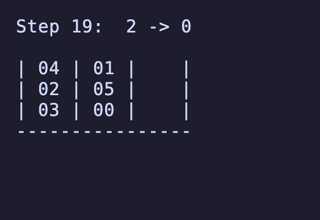
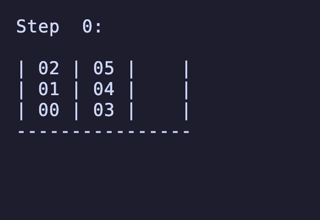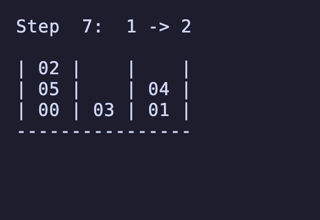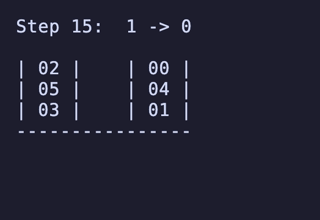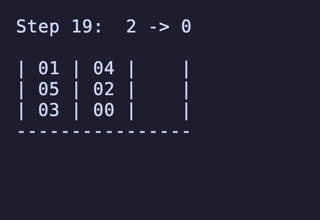
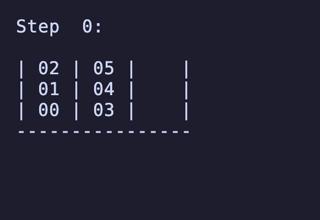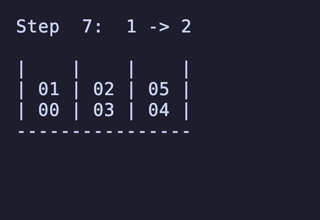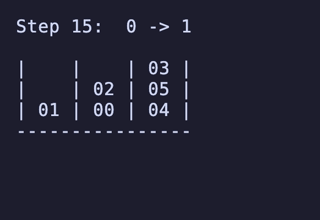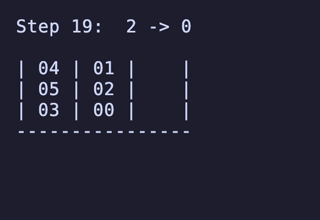
どれも1番下の団子同士が入れ替わり、2段目にあったものは3段目のどちらかに、3段目にあったものは2段目のどちらかに入れ替わる、という操作のもののようだ。
さらに一般化していくと
「高さ3の3本の串に」という条件も変えていってみる。
高さHの N本の串に、H * (N - 1)色の団子を積む、と考えるとどうだろうか。任意の状態に遷移可能だろうか。
到達可能性
最大で H * N の空間となるが、少なくとも H個分の隙間はないと一番下の団子を移動することができないので任意の状態に遷移することは不可能になる。 団子はH * (N - 1)個以下であることは必須だ。
Nは 3以上である必要がありそうだ。「高さ2で2本で2色の団子」の場合を考えると明らかに1本の中で積まれた2色の団子を入れ替える操作が不可能。3本あればどれかを退避させて入れ替える手順が可能になりそうだ(証明は略)。
3本を使って任意の位置のものを一番下に潜り込ませる手順の存在を示すことさえできれば、それを繰り返すことで残りは高さH-1の問題に帰着できる。高さ1で3本なら明らかに任意の状態に遷移可能なので、帰納法で証明できるかもしれない。おそらく3本あればどんな高さでも可能そう。
任意の3本の間で任意の状態に遷移可能であれば、N+1本になってもやはり遷移可能になるはずだ。
従って、ちゃんと証明はできていないけど おそらく「高さHの N本の串に、H * (N - 1)色の団子を積む」というルールは N >= 3 であれば任意の状態に遷移可能である、ということになるだろう。
頂点数
ではそれらの場合に、有り得る状態の総数、つまりグラフの頂点数はどうなるだろうか。
団子の並び方は、 通り。
N = 3, H = 3 なら 6! = 720 通りだった。
配置パターンは、N本の串に H * (N - 1)個の団子を配置する場合の上限つき整数分割の列挙となるが、これは逆にH個分の隙間をどの串に分割するか、と考えた方が簡単。
H個のものをN個に分割するのであれば、N-1個の仕切りとH個の隙間の並べ替えの数となる。これは と計算できる。
よって、これらを掛け合わせた が全状態数となる。
>>> from math import comb, prod >>> f = lambda n, h: prod(range(1, h * (n - 1) + 1)) * comb(n + h - 1, h) >>> f(3, 3) 7200 >>> f(3, 4) 604800
N = 3 なら
H = 1: 6 H = 2: 144 H = 3: 7,200 H = 4: 604,800 H = 5: 76,204,800
と高さ5でかなりの計算量になることが見込まれる。
N = 4 だと
H = 1: 24 H = 2: 7,200 H = 3: 7,257,600 H = 4: 16,765,056,000 H = 5: 73,229,764,608,000
N = 5 だと
H = 1: 120 H = 2: 604,800 H = 3: 16,765,056,000 H = 4: 1,464,595,292,160,000 H = 5: 306,545,653,030,256,640,000
となり、高さ3でもちょっと計算量が大変なことになりそうだ…。団子の個数が増えるととにかく大変。
数千万になってくると計算が少しでも速くなるよう工夫が必要で、複数のStackを使うかわりに高さが8を超えない前提で u64 に8bitずつ詰めて固定数の u64配列で表現したり、それらを格納する HashMap が標準だと遅いので ahash を使って高速化したり、といったチューニングを施した。
本数を固定し、高さを変える
N = 3 で固定して、高さHを変えるとどうなるだろうか。
H = 3 は前述した通り、 7,200頂点 25,920辺 のグラフで 19手が最長の問題だった。
H = 4 だと 604,800頂点 2,419,200辺 のグラフになる。
最長手数は 27手で、[[1, 2, 3, 4], [5, 6, 7, 8], []] のように2本を埋めているものから初めるパターンは11通り存在するようだった。
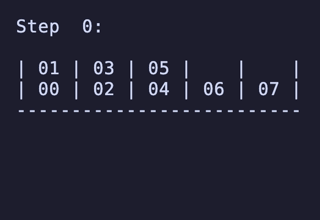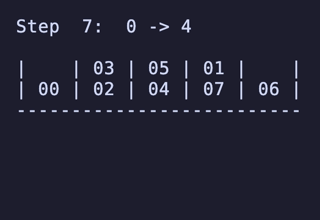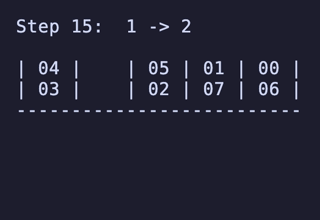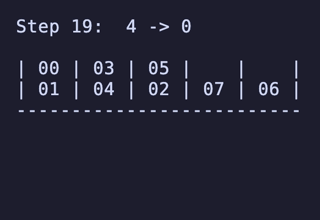
例:
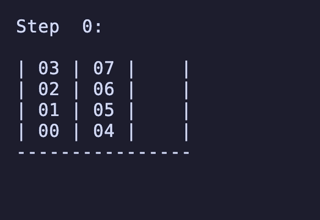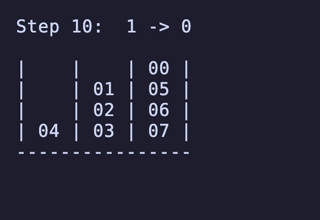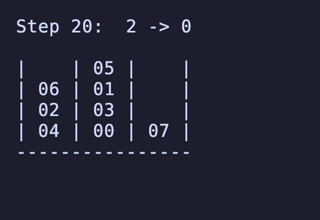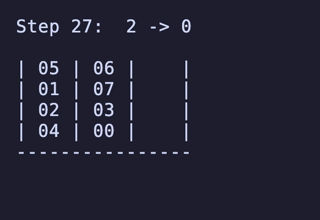
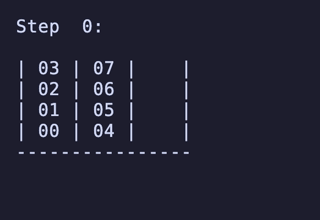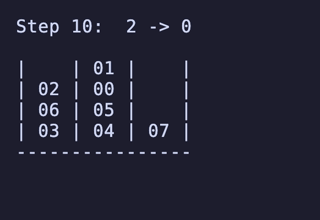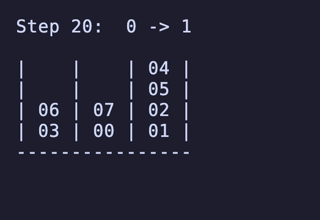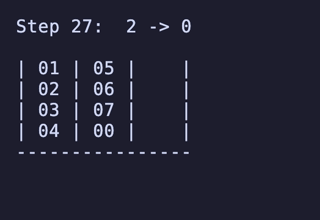
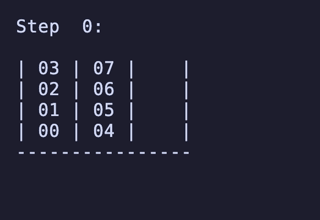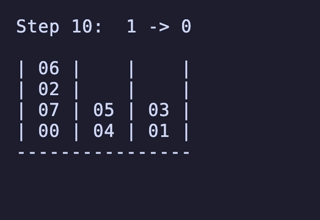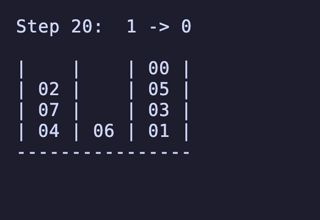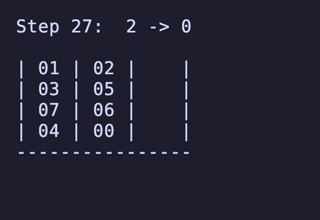
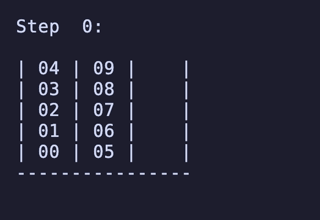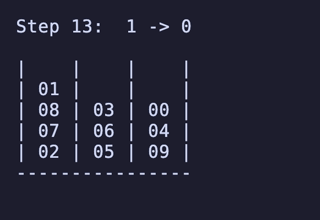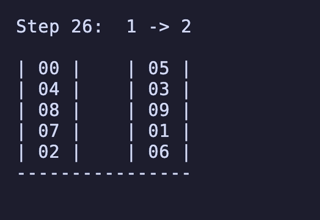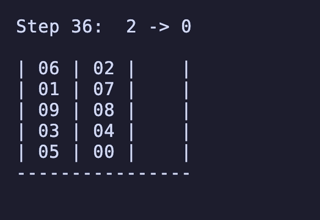
H = 5 だと 76,204,800頂点 326,592,000辺 のグラフになる。
最長手数は 36手で、同様に6通りほど見つかる。
例:
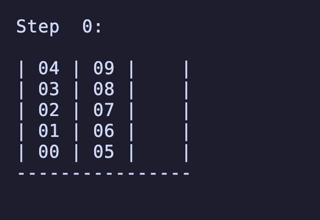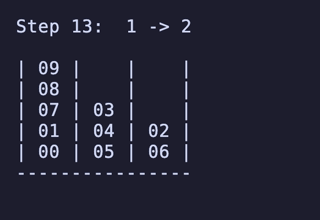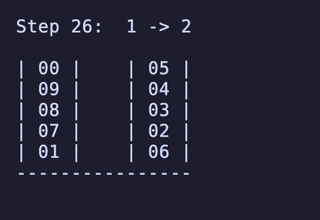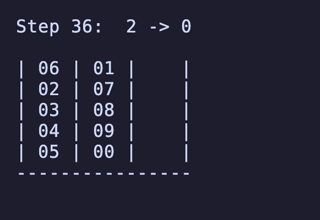
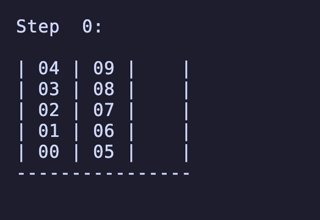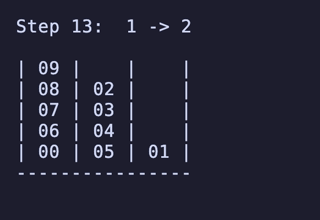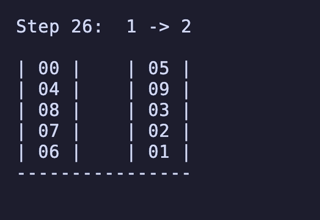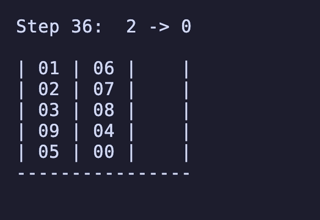
ちょっと法則は見つからなかったが、少なくとも「ハノイの塔」のように指数関数的に手数が増えるということはなさそうだ。
高さを固定し、本数を変える
H = 3 だと計算量が膨大になるので、 H = 2 で固定して N を変えてみる。
N = 3 だと 144頂点 432辺 のグラフになる。 最長は 10手 になる。
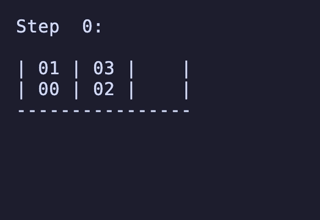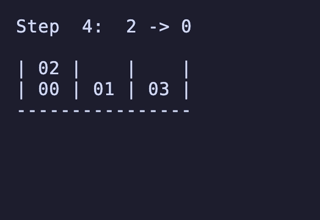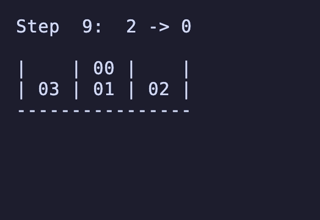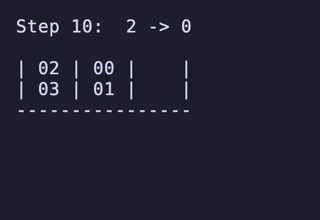
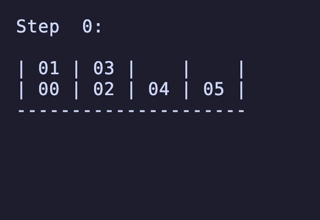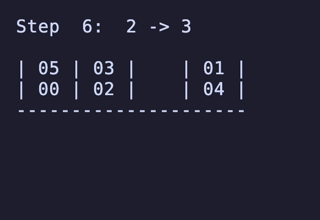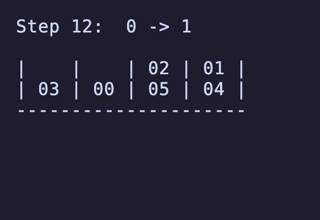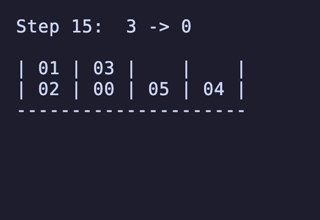
N = 4 だと 7,200頂点 34,560辺 のグラフになる。最長は 15手 で、これは [[1, 2], [3, 4], [5, 6], []] のような形ではなく [[1, 2], [3, 4], [5], [6]] のような形から始めるパターンだけで現れるようだ。
N = 5 だと 604,800頂点 4,032,000頂点 のグラフになる。最長は 19手 で、これもやはり [[1, 2], [3, 4], [5, 6], [7], [8]] のような形からのものだ。
H = 2, N = 4 は H = 3, N = 3 と同じ頂点数だが、辺数が多くなり最長手も短い。
同様に H = 2, N = 5 も H = 3, N = 4 と同じ頂点数だが、辺数が多くなり最長手も短い。高さが無いぶん深く掘るような面倒な手順が減るだろうから、それはそうか。
まとめ
- 「だんご屋のひまつぶし」という面白いパズルがある
- グラフ問題としてプログラムで解くことができる
- 問題集では14手の問題が載っていたが、16手の問題が存在することが分かった
- Webブラウザで動く、一瞬で最短経路を求めることができるものを作った
- 団子の色がすべて異なる場合、串が増えた場合、串がより高くなった場合などについて考察した